1. 사전 준비
먼저 크롤링 하고 싶은 웹사이트의 url을 지정하고 request(요청)하여 아래와 같이 사용할 수 있다.
*request 라이브러리 설치는 [파일] - [설정] - [프로젝트: (프로젝트명)] - [Python 인터프리터] - [+버튼 클릭] + [reqeusts검색 후 인스톨]
import requests
# headers 는 마치 우리가 코드가 아닌 브라우저에서 콜을 날린 것처럼 인식하게 하는 코드다.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.gamemeca.com/ranking.php', headers=headers)
print(data.text)위에선 게임메카 사이트의 게임순위 페이지에서 게임 랭킹을 크롤링하기 위한 준비 작업이다. 위와 같은 코드를 실행하면 HTML문서 전체를 크롤링해서 콘솔에 출력한다.
2. BeautifulSoup 라이브러리 활용
위에서 HTML을 크롤링 해오면 다음은 필요한 데이터만을 추출하기 용이하도록 정제할 필요가 있다. 그 때 사용하는 것이 BeautifulSoup이라는 파이썬 라이브러리다. 위에서 request라이브러리 추가한 것과 같이 bs4와 beaultifulsoup을 설치하자.
이후 코드는 아래와 같이 추가한다.
import requests
from bs4 import BeautifulSoup
# headers 는 마치 우리가 코드가 아닌 브라우저에서 콜을 날린 것처럼 인식하게 하는 코드다.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.gamemeca.com/ranking.php', headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
3. 필요한 부분만 골라오기
소스코드 정제가 완료되면 이제 필요한 부분만 골라오는 작업을 하면 되는데 우리가 이 페이지에서 필요한 정보는 게임랭킹, 게임 타이틀, 제조사 정도다.
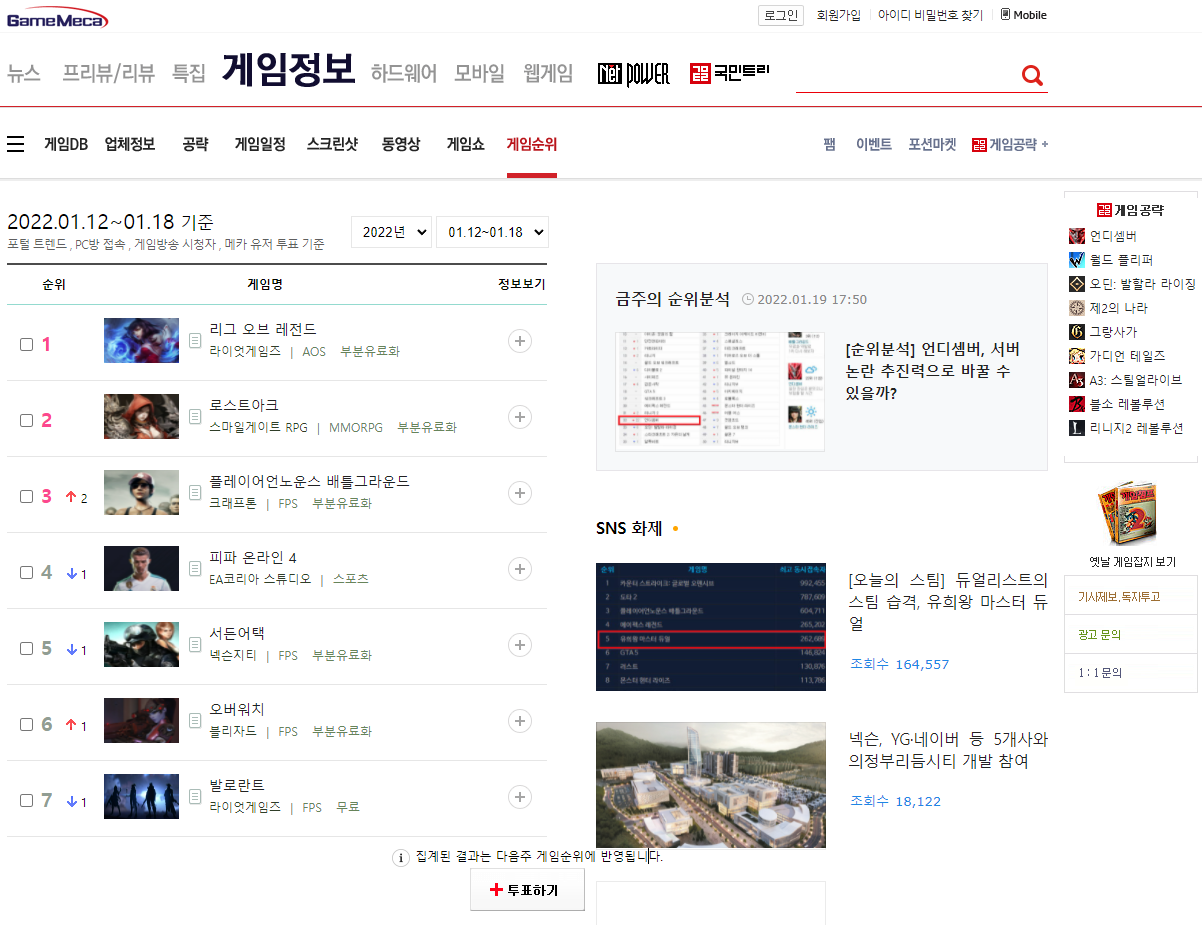
위 페이지에서 순위들 중 하나 위에 커서를 두고 우클릭을 한 후 [검사]를 클릭한다.
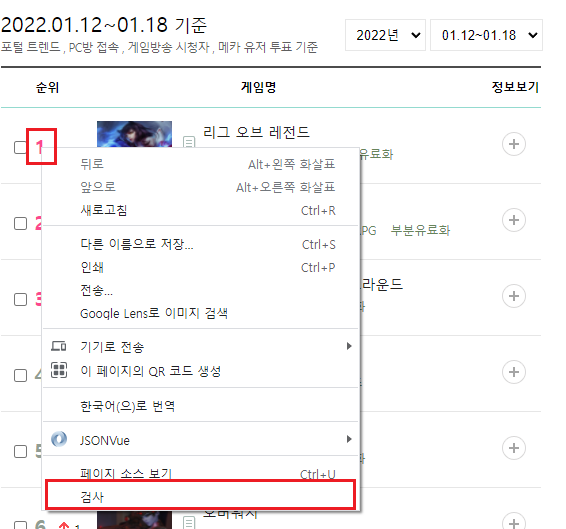
그러면 개발자모드(F12)가 켜지면서 해당 텍스트에 해당하는 코드를 지정하여 보여준다.
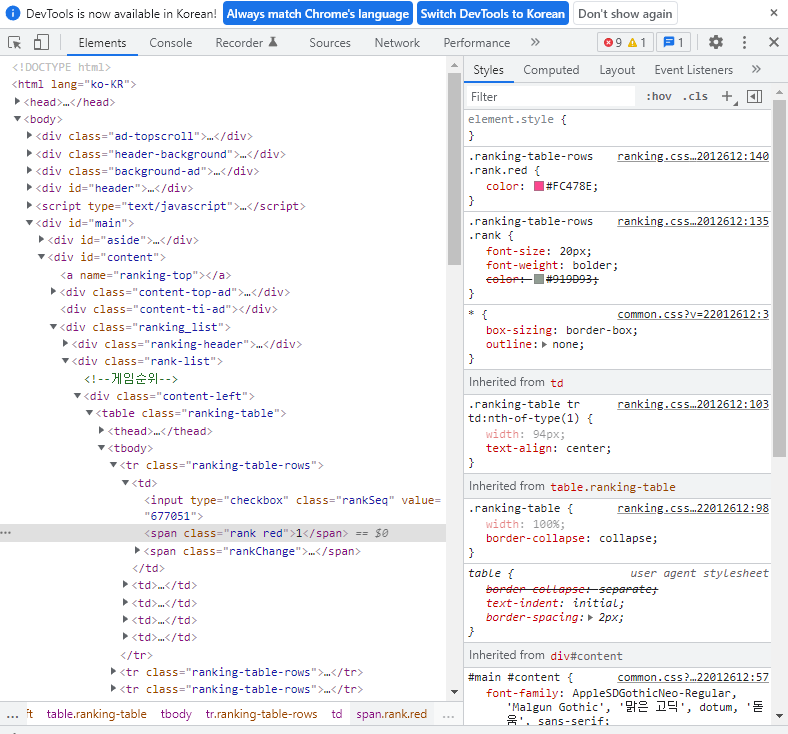
이후 해당 코드에 커서를 두고 마우스 우클릭 후 [Copy] - [Copy selector]를 클릭한다.
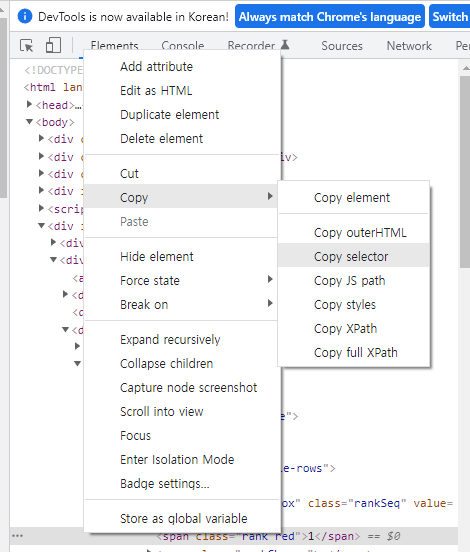
복사한 내용을 붙여넣기 해보면 아래와 같은 태그가 복사된 걸 알 수 있다.
(1)게임 순위
#content > div.ranking_list > div.rank-list > div.content-left > table > tbody > tr:nth-child(1) > td:nth-child(1) > span.rank.red(2)게임 타이틀
#content > div.ranking_list > div.rank-list > div.content-left > table > tbody > tr:nth-child(1) > td:nth-child(4) > div.game-name > a(3)제조사
#content > div.ranking_list > div.rank-list > div.content-left > table > tbody > tr:nth-child(1) > td:nth-child(4) > div.game-info > span.company > a
한 개의 게임 정보만을 가지고 올게 아니라 랭킹 전체를 가져오기 위해서 위 태그 전체가 아니라 아래까지만 활용한다.
#content > div.ranking_list > div.rank-list > div.content-left > table > tbody > tr위 태그는 아래와 같이 select를 활용하여 사용할 수 있다.
games = soup.select('#content > div.ranking_list > div.rank-list > div.content-left > table > tbody > tr')우리가 필요한 정보는 '순위', '타이틀', '제조사' 정도이기 때문에 아래와 같이 for문을 돌려서 추출할 수 있다.
for문을 돌릴 때 각각 원하는 정보를 얻기 위해 중복되었던 태그와 인덱스 코드 뒤에 있는 각 정보의 고유 코드를 붙여서 가져온다.
for game in games:
rank = game.select_one('span.rank').text
name = game.select_one('div.game-name > a').text
company = game.select_one('div.game-info > span.company > a').text
print(rank, name, company)
크롤링 완성한 코드는 아래와 같다.
import requests
from bs4 import BeautifulSoup
# headers 는 마치 우리가 코드가 아닌 브라우저에서 콜을 날린 것처럼 인식하게 하는 코드다.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.gamemeca.com/ranking.php', headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
games = soup.select('#content > div.ranking_list > div.rank-list > div.content-left > table > tbody > tr')
for game in games:
rank = game.select_one('span.rank').text
name = game.select_one('div.game-name > a').text
company = game.select_one('div.game-info > span.company > a').text
print(rank, name, company)위 코드를 실행하면 아래와 같이 정상 추출된 것을 알 수 있다.

여기서 추출한 데이터를 바탕으로 페이지에 구현한다던지 DB에 입력하는 등으로 가공 및 활용할 수 있겠다.
'Programming > Python' 카테고리의 다른 글
| [Python] Call by reference & Call by Value, 불변타입과 가변타입 (0) | 2022.03.26 |
|---|---|
| [Python] f-string에 대해서 (0) | 2022.02.20 |